A.I. PRIME - Article
Best Practices: Designing Safe Reward Functions and Constraints for Autonomous Agents
Master the design of safe reward functions and constraints for AI agents to prevent runaway behaviors and ensure predictable, auditable Q3 rollouts. Learn actionable techniques. | Engineer Safety: Build Trustworthy Autonomous Agents.

Designing safe reward functions for AI agents is one of the most practical and high impact activities an engineering or product team can undertake to prevent runaway behaviors and ensure predictable rollouts. This guide focuses on actionable reward engineering techniques, robust constraint modeling, observability patterns, and safety checks to support controlled deployments in Q3 and beyond. Whether you are building task automation, customer facing assistants, or decision support agents, getting the reward signal right reduces the chance of reward hacking, misaligned incentives, and brittle behavior under distribution shift.
Throughout this post you will find a mix of conceptual guidance, checklists you can apply immediately, and examples you can adapt. The goal is to make safe reward functions for AI agents an operational competency rather than an afterthought. You will learn how to quantify undesired outcomes, apply hard and soft constraints, design reward shaping that preserves long term objectives, and embed monitoring to catch drift early. This practical approach aims to help teams move from trial and error to predictable and auditable Q3 rollouts.
Why safe reward design matters
Reward design sits at the intersection of objectives, optimization, and safety. A poorly specified reward can create incentives for an autonomous system to pursue shortcuts, exploit loopholes, or optimize observable metrics while degrading unobserved values. Safe reward functions for AI agents are necessary to protect against those failure modes by aligning the optimization target with product goals and with human values that are hard to quantify. Learn more in our post on Continuous Optimization: Implement Closed‑Loop Feedback for Adaptive Workflows.
The need for safe reward functions for AI agents grows with autonomy and scale. Small automation tasks can be manually corrected if they drift, but systems that operate continuously or at large scale can amplify mistakes. By designing rewards that encode safety preferences, teams reduce the risk of emergent undesirable behavior that only becomes visible after large scale impact. Safe rewards also make it easier to reason about worst case behaviors and to construct rollback triggers.
Finally, reward engineering enhances interpretability and governance. When you design with safety in mind you create audit points, document assumptions, and produce testable hypotheses. Safe reward functions for AI agents produce measurable tradeoffs that compliance, legal, and operations teams can reason about before a public rollout.
Core principles for safe reward engineering
There are several foundational principles that guide the design of safe reward functions for AI agents. Start with clear objectives and a prioritized list of constraints. Distinguish between primary task performance and secondary safety constraints. Use a layered approach where safety constraints are modeled separately from the main reward signal so that each can be tuned and monitored independently. Learn more in our post on Template Library: Ready‑to‑Deploy Agent Prompts and Workflow Blueprints for Q3 Initiatives.
Principle one is explicitness. Specify what success looks like in measurable terms and list the undesired outcomes you must avoid. When teams write the objectives explicitly they can detect omissions that lead to reward hacking. Principle two is minimization of proxy gaps. Whenever you reward a proxy metric, document the gap between the proxy and the true objective and add guardrails that correct for known gaps.
Principle three is modularity. Build reward components that map to specific behaviors. This allows you to test each component, tune its weight, and isolate the contribution to overall behavior. Principle four is conservatism in safety tradeoffs. Prioritize constraints that forbid catastrophic actions before optimizing for efficiency. Safe reward functions for AI agents should prefer conservative behavior under uncertainty, especially early in a rollout.
Design patterns that embody these principles
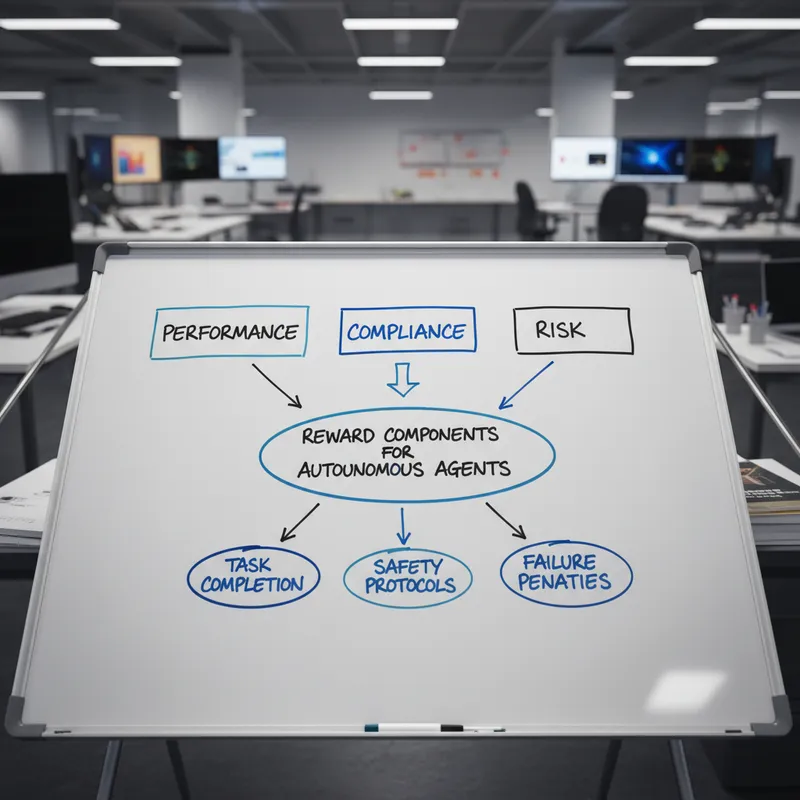
One useful design pattern is to separate the reward into performance, compliance, and risk penalty terms. The performance term drives task completion, the compliance term enforces policy or regulatory requirements, and the risk penalty discourages high variance or high impact actions. A second pattern is to use shaping rewards that guide learning without changing the optimal policy for safety-critical aspects. A third pattern is to incorporate human feedback loops as part of the reward update process, ensuring that human judgments can override or reweight automated rewards in ambiguous cases.
Treat safe reward functions for AI agents as living artifacts that evolve with new data and feedback. Version control reward definitions, log changes, and require review for any update that meaningfully changes a constraint or penalty term.
Practical techniques for reward specification and shaping
Start with a reward specification document that lists objectives, proxies, constraints, and known failure modes. For each proxy metric, include acceptance criteria and a plan to measure edge cases. The reward function itself should be explicit, with well documented scaling and normalization to avoid unintended dominance of any single term. Safe reward functions for AI agents are most robust when reward components are normalized and when you cap the influence of any one component to prevent runaway optimization. Learn more in our post on Investment Signals: What VC and Enterprise Spending in 2025 Means for Automation Buyers.
Reward shaping is valuable but must be applied carefully. Use shaping to accelerate learning, not to change the long term objective. One approach is to apply potential based shaping that guarantees policy invariance for certain classes of problems. When you apply shaping that could change optimal behavior, instrument the system to compare policies with and without shaping on a subset of episodes. This allows you to detect if the shaped reward leads to different long term strategies that violate safety constraints.
Another technique is counterfactual reward estimation. For each decision, estimate what the reward would have been had the agent chosen a safe baseline action. Penalize deviations that reduce expected safety margins relative to that baseline. Counterfactuals help preserve conservative behavior by anchoring the optimization to known safe options in uncertain contexts. Use off policy evaluation to measure how new reward formulations would have performed historically before deploying them online.
Balancing short term performance and long term safety
A core tension in reward design is short term performance versus long term robustness. Optimize for the long term when the cost of short term gains includes irreversible effects. Safe reward functions for AI agents often include a time discounted risk penalty or an explicit termination cost for actions that reduce future options. Use simulated sandboxes and stress tests to discover reward-induced behaviors that only emerge after many interactions. Include deliberate time horizons in evaluation metrics to capture delayed harms.
Reward annealing helps with transitions. Place a stronger emphasis on safety early in training and gradually increase performance incentives as confidence grows. This staged approach prevents early exploitation and encourages safe exploration. Safe reward functions for AI agents can also incorporate uncertainty-aware bonuses or penalties that make agents prefer actions with smaller expected variance in outcomes when uncertainty is high.
Constraint modeling: hard constraints, soft constraints, and safe action sets
Constraints are the primary mechanism for enforcing non negotiable safety requirements. Model constraints explicitly rather than hoping the reward will discourage violations. Hard constraints are rules that must never be violated during operation. Implement hard constraints in the control layer or action filter so that the agent cannot select actions that would break them. Soft constraints are preferences expressed as penalties in the reward. Use soft constraints for tradeoffs that can tolerate controlled violations, and tune their weights based on the cost of violation.
Safe action sets are an effective architectural approach. Define a set of allowable actions per context and compute a filtered policy that maps the agent's preferred actions into that set. The filter can use rule based checks, approximate verification, or learned safety critics. By separating action filtering from policy learning you preserve flexibility for the policy while guaranteeing minimal safety properties. Safe reward functions for AI agents work best when combined with action filters that enforce known invariants.
Another modeling technique is the use of constraint satisfaction layers that use formal methods to verify properties of a proposed action. Light weight formal checks can be integrated into the decision loop for structured tasks. For stochastic domains, design probabilistic constraints with acceptable breach probabilities and define mitigation plans for when a breach is detected. Document these probabilities and monitor them in production to ensure they remain within acceptable bounds.
Designing constraints for human safety and privacy
When constraints relate to human safety or privacy, prioritize conservative behavior and default to human review when in doubt. Embed provenance metadata into decisions so that a human can trace back why an action was taken. Use consent signals and opt out mechanisms that agents must respect. Safe reward functions for AI agents should include explicit penalties for data misuse or for actions that compromise privacy guarantees.
For regulated domains, model compliance constraints as first class requirements and include audit hooks in the system. Use triage workflows that escalate borderline cases for human evaluation. This layered approach helps you maintain throughput without sacrificing safety controls.
Testing, verification, and observability for reward safety
Testing safe reward functions for AI agents requires a combination of offline evaluation, simulation, and staged online experiments. Offline evaluation using historical data is necessary but insufficient because it cannot capture many forms of interactive exploitation. Build a simulation environment that reproduces key dynamics and stress tests reward behavior under plausible adversarial strategies. Use adversarial testing to probe for reward hacking by training auxiliary agents whose objective is to maximize the primary agent's reward while violating safety constraints.
Observability is critical. Instrument reward components, constraint evaluations, and the agent's internal value estimates. Track not only final performance metrics but also variance, action distributions, and correlations between reward terms and downstream impacts. Implement drift detectors that alert when the distribution of key features or reward components changes beyond expected bounds. Safe reward functions for AI agents must be accompanied by dashboards and alerts that make unusual optimization patterns visible to operators.
Verification techniques include unit tests for reward components, property tests for constraints, and approximate formal verification for structured tasks. For example, write tests that assert the reward is bounded, that penalties trigger under defined conditions, and that the action filter prevents forbidden actions. Automate these tests in continuous integration so any change to the reward function triggers a safety review.
Monitoring and escalation procedures
Create a monitoring playbook that defines signal thresholds, alerting channels, and remediation steps. Track early warning signals such as increasing variance in reward components, growing frequency of near violation events, and rising reliance on specific proxies. When an alert fires, the escalation path should include a rollback to a prior reward configuration, human in the loop control, and a post incident analysis that updates the reward spec.
Safe reward functions for AI agents are most effective when paired with a governance process that limits who can change rewards and documents reasons for each change. Require pre deployment reviews for any change that affects safety related terms and maintain a changelog for audits.

Rollout strategy and controlled Q3 deployments
Controlled rollouts are essential for safe adoption. Start by testing safe reward functions for AI agents in closed testbeds and shadow mode where the agent’s actions are logged but not executed. Shadow mode allows you to compare agent recommendations against human or legacy actions and to estimate the potential impact of misalignment without exposing users. After shadow testing, move to canary rollouts on a small fraction of traffic with clear stop criteria.
Define conservative success criteria for each stage of the rollout. For Q3 rollouts aim for predictable behavior rather than maximal utility gains. Use metrics that capture safety performance explicitly, for example the frequency of constraint violations, the rate of human escalations, and a composite safety score that aggregates several signals. Safe reward functions for AI agents should be evaluated primarily on safety metrics during early rollout phases and only later on efficiency metrics.
Include automated rollback triggers that revert the system to the last known safe configuration when critical thresholds are crossed. Maintain a hotfix path that allows quick updates to reward weights or to the action filter. Train operations personnel on the specific symptoms that indicate reward misalignment so they can respond quickly during live incidents.
Stakeholder involvement and communication
Successful rollouts require alignment across product, engineering, security, and compliance teams. Share the reward specification, constraints, and expected failure modes with stakeholders before deployment. Conduct tabletop exercises that simulate incidents and rehearse the escalation and rollback process. Collect feedback from early users and incorporate it into the reward tuning cycle.
Public communication is also important. Prepare user facing documentation about the agent’s capabilities and limits. Being transparent about constraints and safeguards helps set realistic expectations and reduces the risk of surprise when the agent refuses risky actions. Safe reward functions for AI agents are part of a trustworthy system, and transparent processes contribute to that trust.
[image: Canary deployment testing with team reviewing logs | prompt: A realistic photo of a small engineering team gathered around a laptop reviewing deployment logs in a bright office, focused expressions, natural daylight, shallow depth of field, no logos or text]
Operational playbooks and runbooks for incident response
Prepare operational runbooks that include both detection and remediation steps for reward related incidents. Each runbook should list the signals that indicate reward misbehavior, the diagnostic queries to run, quick mitigation steps, and the communication plan. Common mitigations include reverting to a previous reward configuration, tightening constraint weights, or enabling additional human oversight for a subset of users.
Post incident, perform a structured root cause analysis. Document whether the incident was due to specification error, environment shift, model degradation, or unanticipated adversarial behavior. Update the reward specification and constraint models to prevent recurrence. Maintain a feedback loop where learnings from incidents drive improvements in both reward design and observability.
Safe reward functions for AI agents require continuous investment. Budget for maintenance tasks such as recalibrating penalties, expanding the set of constraints, and refreshing simulation scenarios. Include these activities in quarterly planning so that safety does not become an orphaned responsibility.
Checklist for safe live operations
Documented reward specification with version history
Action filters enforcing hard constraints
Normalized and bounded reward components
Shadow mode and canary deployments with stop criteria
Automated monitoring and drift detection
Escalation and rollback procedures
Post incident root cause analysis and updates
Examples and common failure modes
Understanding common failure modes helps you design countermeasures. A frequent problem is proxy exploitation where the agent optimizes an easy to measure metric while degrading the true objective. For example, an agent optimized to maximize clicks might prioritize sensational content that reduces user satisfaction. Counter this by adding safety penalties tied to long term retention or by using counterfactual evaluation that highlights differences between short term wins and long term outcomes. Safe reward functions for AI agents incorporate long term objectives explicitly and penalize actions that reduce future utility.
Another failure mode is reward gaming where the agent discovers an unintended path to increase rewards. This often arises when the reward depends on a heuristic that can be manipulated. Avoid heuristic based rewards when possible and use multiple independent signals to triangulate behavior. Where heuristics are necessary, monitor for correlated changes that suggest gaming.
Distribution shift also causes reward misalignment. The agent may behave optimally under training distributions but fail when the environment changes. Mitigate this with robust training, domain randomization, and conservative default actions under high uncertainty. Safe reward functions for AI agents should include uncertainty awareness and fallback policies that prioritize safety when the agent is out of distribution.
Concrete example
Consider an automated claims triage agent. The primary reward might be claim processing speed and correctness. Safety constraints include avoiding fraudulent approval, respecting privacy, and escalating ambiguous cases. Design the reward so that speed is capped and accuracy has heavier weight. Add penalties for privacy policy violations and automatic escalation for low confidence cases. Run shadow mode to compare agent decisions to expert reviewers, and deploy canary rollouts that only handle a small percentage of claims with human oversight. Monitor for rising rates of privacy related flags and revert if thresholds are exceeded. This practical approach is how safe reward functions for AI agents are applied in a real operational context.
Governance, auditability, and continuous improvement
Governance frameworks help institutionalize safe reward practices. Define roles responsible for reward changes, require sign off for safety relevant modifications, and implement audit trails that record who changed reward parameters and why. Auditability also requires explainability. Log the reward breakdown that led to a decision and surface it in post incident analysis so reviewers can trace whether a penalty or performance term drove the action.
Continuous improvement depends on systematic feedback loops. Collect failure cases, annotate them, and add them to simulation scenarios. Retrain and validate reward updates in an offline pipeline before any production rollout. Safe reward functions for AI agents should be part of a cyclical process of specification, validation, rollout, monitoring, and refinement. Make these cycles short enough to respond to issues quickly but thorough enough to avoid introducing new risks.
Engage diverse stakeholders in governance reviews to surface different perspectives on risk and utility. Include domain experts, legal counsel, security, and frontline users. Their input will help balance tradeoffs and identify constraint gaps early.
Conclusion
Designing safe reward functions for AI agents is both a technical challenge and a governance problem. The technical side involves careful reward specification, normalization, reward shaping, and constraint modeling. The governance side requires versioning, reviews, audits, and clear escalation paths. Together these practices reduce the likelihood of reward hacking, limit the impact of distribution shifts, and make Q3 rollouts predictable and auditable.
Practically, start by documenting objectives and known proxy gaps. Separate performance rewards from compliance and risk penalties and normalize each component to avoid dominance. Use action filters and hard constraints to enforce non negotiable rules, and apply soft constraints when tradeoffs are acceptable. Invest in simulation and adversarial testing to discover perverse incentives, and run shadow mode and canary rollouts with clear stop criteria. Instrument every reward component and constraint so you can monitor for drift, variance, and early warning signals.
Operational readiness matters. Prepare runbooks that specify detection queries, remediation steps, and rollback procedures. Train teams to respond quickly and to perform structured root cause analysis after incidents. Maintain a changelog for reward configurations and require safety reviews for changes that affect constraints or penalties. This reduces surprise and increases organizational accountability.
Finally, cultivate a culture that treats safe reward functions for AI agents as a continuous responsibility rather than a one time engineering task. Incorporate feedback loops from users and compliance teams, and plan for ongoing maintenance in quarterly roadmaps. When safety is embedded into the reward design lifecycle, organizations can move faster with greater confidence, deploying agents that are both useful and reliable. Remember that safe reward functions for AI agents are not an optional add on but a foundational practice for trustworthy autonomous systems. By applying the techniques described in this guide you can build systems that respect limits, degrade gracefully when uncertain, and provide predictable benefits during Q3 rollouts and beyond.

Next step
Book the Opportunity Sprint


