A.I. PRIME - Article
From Pilot to Production: Your 90-Day Agentic AI Deployment Blueprint
Accelerate agentic AI adoption with a proven 90-day deployment framework that moves from pilot to production while maintaining governance and measurable.

Founder-led teams and small B2B operators don't have the luxury of lengthy AI pilots. You need a clear, time-boxed approach that moves from proof of concept to measurable operational impact in 90 days. This Rapid Deployment Kit provides a structured 30 - 60 - 90 day blueprint to accelerate agentic AI adoption while maintaining governance, security, and measurable ROI. The goal is to reduce time to value, validate assumptions quickly, and scale with confidence when outcomes meet defined success criteria.
This deployment plan distills proven patterns into actionable phases. Days 1 - 30 focus on rapid discovery and a focused pilot with measurable KPIs. Days 31 - 60 expand scope, harden governance, and operationalize monitoring. Days 61 - 90 transition to production scale with clear reporting and a roadmap for sustained improvement. The plan is practical, repeatable, and designed to balance velocity with control so that your investment in agents delivers predictable outcomes.
Why a Time-Boxed Deployment Plan Matters for Fast-Moving Teams
Deploying agentic AI without structure leads to scope creep, unclear ROI, and unmanaged risk. A 30 - 60 - 90 day plan forces disciplined decisions and aligns priorities across your team. Time-boxing creates momentum by focusing work on defined outcomes, which reduces indecision and accelerates stakeholder buy-in. It also creates natural review points where you can validate assumptions and either scale successes or pivot with minimal sunk cost. Learn more in our post on Rapid Deployment Kit: A 30–60–90 Day Agentic AI Rollout.
From a governance perspective, a structured plan allows you to assess safety, privacy, and compliance early in the process. It establishes data use agreements and logging requirements before agents operate on production data. From a technical perspective, the plan clarifies integration boundaries, monitoring requirements, and rollback procedures so that experiments don't expose your broader environment. From a business perspective, it prioritizes use cases that generate measurable value and reduces time to value by focusing on outcomes rather than features.
Operationalizing agentic AI requires both engineering and organizational readiness. This deployment plan makes those dependencies explicit. It prescribes roles, sprint goals, and review gates to ensure your team works in lockstep. The plan encourages minimal viable agent designs that are constrained to specific tasks, which reduces risk and simplifies validation. In short, time-boxed execution converts strategic ambition into operational reality.
Core Principles That Drive Successful Deployments
The following principles guide an effective agentic AI deployment. Embed them into every decision point throughout your 90 days. Learn more in our post on Rapid Deployment Playbooks: From Pilot to Production in 90 Days.
Outcome focus: Define specific business outcomes and measurable metrics before building. Avoid vague goals and focus on what constitutes success during each timebox.
Guardrails first: Establish safety, privacy, and compliance rules up front. Agents must have constraints, logging, and oversight to operate safely.
Minimum viable agent: Build the smallest agent that can prove the hypothesis. Start with narrow capabilities to reduce integration complexity and time to validation.
Iterative validation: Use rapid feedback loops and test in controlled environments. Validate assumptions frequently and make go - no-go decisions at each checkpoint.
Platform reuse: Use modular and reusable components such as connectors, observability pipelines, and governance patterns to accelerate subsequent deployments.
Clear ownership: Assign accountable owners for outcomes, model performance, data quality, and compliance. Clear responsibilities reduce coordination overhead.
Days 1 - 30: Fast Pilot and Proof of Concept
The first 30 days emphasize rapid discovery, hypothesis definition, and a focused pilot. Your goal is to validate the value proposition with a working prototype and measurable evidence. A concise deployment plan for this phase should include stakeholder alignment, a prioritized use case, data readiness checks, and a proof of concept that demonstrates baseline outcomes. Learn more in our post on Scale AI from Pilot to Production: A CDO's Essential Checklist.
Start with stakeholder workshops to align objectives and success metrics. Create a project charter that maps the desired outcome to measurable KPIs. Choose a use case that is high impact and low integration complexity - this could be a task automation scenario or a decision support agent that augments a specific team. Use the minimum viable agent concept to constrain scope and reduce risk. For example, a support team might deploy an agent to qualify and categorize incoming tickets, or a sales team might use an agent to prioritize follow-up leads based on engagement signals.
Technical setup focuses on a safe sandbox environment, basic observability, and simple connectors to required data sources. Implement initial logging and telemetry so that agent actions are auditable from day one. Establish a rollback plan and ensure your team can quickly disable the agent if issues arise. During this sprint, conduct early testing with a controlled set of users to collect qualitative and quantitative feedback. Track metrics like accuracy, speed, error rates, and user satisfaction.
Deliverables at the 30-day checkpoint should include a working prototype, a results summary against defined KPIs, an initial risk assessment, and a clear go-forward recommendation. If the pilot meets predefined success criteria, prepare to expand scope in the next timebox. If not, document learnings and iterate or pivot as needed. This checkpoint is critical - it's where you decide whether to invest the next 60 days in scaling.
30-Day Checklist
Define outcome and measurable success criteria with stakeholders
Select minimum viable agent use case aligned to business priorities
Provision sandbox environment and data connectors
Implement basic logging and telemetry for auditability
Run controlled user tests and gather feedback systematically
Produce a pilot results report with risk assessment and recommendation
Days 31 - 60: Expansion and Operational Hardening
The second 30-day period builds on the pilot and focuses on robustness, broader user adoption, and deeper integration. Your goal at the 60-day milestone is to refine the agent, scale its usage to more users or datasets, and harden governance and monitoring. This period also addresses performance optimization and operational readiness so you're prepared for production.
Begin by analyzing pilot telemetry to identify failure modes, friction points, and opportunities for improvement. Expand the test population progressively to ensure performance holds at scale. During this period, add necessary connectors and workflows so that the agent integrates with your broader operational environment. Strengthen data validation and implement transformation pipelines to improve data quality. For example, if your pilot agent was handling support tickets, you might now integrate it with your CRM, knowledge base, and escalation workflows.
Governance activities intensify during this sprint. Finalize access controls and ensure audit logging is comprehensive. Implement alerting for anomalous agent behavior and set escalation paths for human intervention. Validate that privacy and compliance requirements are consistently met across new integrations. Update deployment plan artifacts to reflect lessons learned and incorporate improved fallback strategies. Document which decisions the agent can make autonomously and which require human review.
Operational teams should work toward automation of routine tasks such as incident triage, retraining triggers, and model version control. Establish runbooks for common failure scenarios so your support team knows how to respond when issues arise. Ensure the operations organization is trained on how to interpret agent outputs and intervene when needed. At the 60-day checkpoint, present an updated performance report, an operational model, and a clear recommendation for scaling to production in the final 30-day period.
60-Day Checklist
Scale user population and datasets gradually with monitoring
Harden connectors, data validation, and error handling
Finalize access controls and comprehensive audit logging
Implement monitoring, alerting, and documented runbooks
Train operations and support teams on agent behavior and intervention
Update deployment plan with operational playbooks and SLAs

Days 61 - 90: Production Rollout and Sustained Impact
The final 30-day period transitions the agent from controlled deployment to production scale. Your objective is to operationalize the agent across targeted business units, embed it into live workflows, and ensure sustained governance. The 90-day milestone should deliver measurable business impact and a clear path to broader scaling.
Key activities include migrating configuration and models to production-hardened infrastructure, ensuring redundancy and failover. Complete integration testing with production systems, perform load testing, and validate performance against agreed service levels. Make sure access controls and data protections are enforced in production environments exactly as they were during testing. If your agent was handling support tickets in a sandbox, now it handles real tickets for real customers - with full monitoring and human oversight in place.
At this stage, build organizational capability for continuous improvement. Establish a cadence for evaluating agent performance, retraining schedules, and periodic compliance reviews. Create a roadmap for additional use cases that reuse the platform components and governance practices established during the first 90 days. Provide transparent reporting to stakeholders showing actual impact versus the original target metrics. This reporting is critical for securing budget and buy-in for phase two.
Close the 90-day loop with a comprehensive post-implementation review. Document successes, shortcomings, and a prioritized list of enhancements for the next phase. If the agent meets or exceeds the success criteria defined in your deployment plan, proceed to scale the solution across more teams and processes with the confidence that governance, monitoring, and operational playbooks exist to manage risk. If results fall short, analyze root causes and decide whether to pivot, iterate, or pause.
90-Day Checklist
Finalize production migration with redundancy and failover
Perform comprehensive integration and load testing
Implement lifecycle and version control for models and agent logic
Set retraining and maintenance cadences based on performance drift
Provide stakeholder reporting with ROI analysis and impact metrics
Document runbooks, scaling roadmap, and next use cases
Security, Privacy, and Governance Throughout the Deployment
Security and privacy are not optional when deploying agentic AI at speed. Your deployment plan must define required controls and how they will be validated. This includes access management, data minimization, encryption in transit and at rest, and robust logging to support forensic analysis. The plan should include a clear process for approving agents to operate on sensitive data and for removing access if anomalous behavior is detected.
Governance is both a set of technical controls and a human process. Define roles for model owners, data stewards, and governance reviewers. Create a lightweight approval workflow that can gate changes without becoming a bottleneck. Establish criteria for when an agent must be paused for human review, and make the criteria objective and testable. Incorporate automated checks into your deployment pipeline so that governance is enforced programmatically where possible.
Privacy considerations must be embedded into design choices from day one. Use data minimization and synthetic data where feasible for testing. Maintain traceability of data lineage so that any output can be traced back to inputs. Ensure that logging retains sufficient context for auditing while avoiding unnecessary exposure of personal data. Finally, plan for regular compliance audits and make remediation part of your continuous improvement process.
Governance Playbook Essentials
Define data classification and agent access rules at the start
Automate policy checks in CI/CD pipelines before deployment
Require explicable action trails for all agent decisions
Set clear thresholds for human intervention and safe shutdown
Schedule periodic risk reviews and compliance audits quarterly
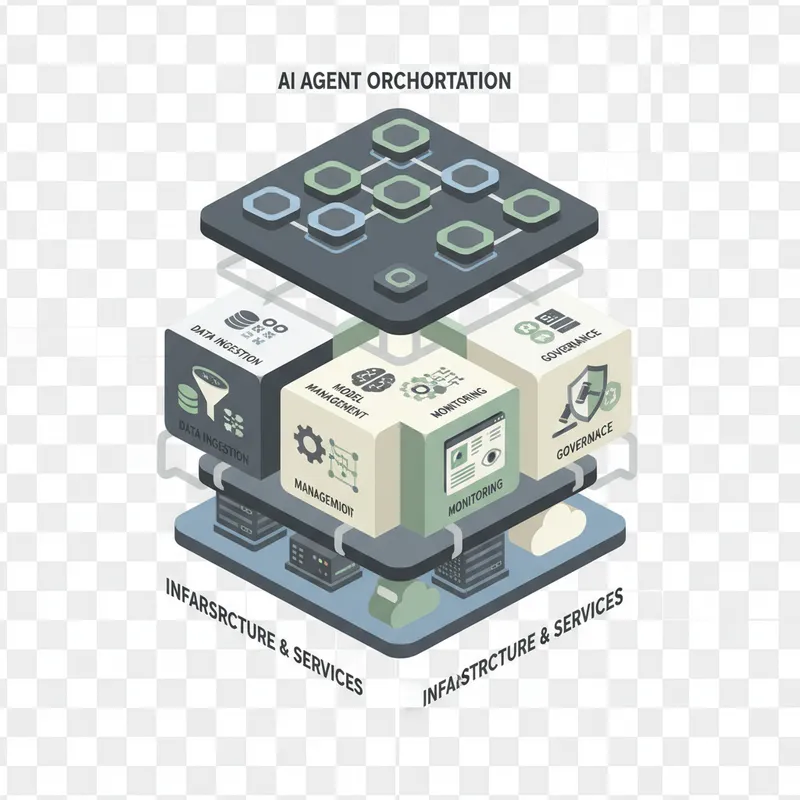
Technology, Architecture, and Observability Patterns
Technical architecture for your deployment must prioritize modularity, observability, and resilience. Modular architecture separates the agent logic from integration adapters, data pipelines, and monitoring. This separation enables reuse across use cases and simplifies testing. Use containerization and orchestration for scalable deployments, and consider managed services where appropriate to reduce operational overhead.
Observability is essential. Instrument agents to capture inputs, decisions, confidence scores, and downstream effects. Aggregate telemetry into dashboards that correlate agent activity with business impact. Implement anomaly detection to surface unusual patterns in agent behavior and data drift. Integrate observability with incident management so that alerts trigger the right human workflows. For a support agent, this means tracking ticket resolution time, accuracy, escalation rate, and customer satisfaction alongside system metrics.
Design for graceful degradation. Agents should fail safe and provide human fallback options when confidence is low. Implement throttles and circuit breakers to protect upstream systems from unexpected load. Use versioned APIs and feature flags to enable incremental rollouts and quick rollbacks. Your deployment plan should include templates for these patterns so they are applied consistently across deployments and future use cases.
Measuring Success and Demonstrating ROI
Measuring impact requires both leading indicators and outcome metrics. Define metrics that map directly to the business outcome identified at the start. For example, measure time saved, error reduction, throughput improvements, or revenue influenced. Use A/B tests or canary rollouts where possible to validate causality. Include qualitative measures such as user satisfaction and adoption rate alongside quantitative KPIs.
Set reporting cadences that align with stakeholder expectations. Produce a concise dashboard that updates in near real time and an executive summary that highlights the bottom-line impact. For your deployment plan, the most persuasive evidence often comes from a combination of a successful pilot demonstrating statistical improvement and a realistic scaling plan that projects full value realization. Include sensitivity analysis to show upside and downside scenarios.
Finally, quantify operational costs and compare them against the value delivered. Include development, infrastructure, monitoring, and governance costs in the analysis. Present a clear payback timeline and outline how the platform and reusable components will reduce costs for future deployments. This makes investment decisions easier and supports continued funding for scaling. For example, if your support agent saved 20 hours per week in the pilot, project that across your full support team and compare the cost of the agent platform against the savings.

Organizational Change Management and User Adoption
Technology is only part of the equation. Adoption depends on people and processes. Your deployment plan must include a change management strategy that prepares users for new ways of working. Identify early adopters and subject matter champions who can validate functionality and evangelize benefits. Provide role-based training that focuses on how agents change daily workflows and how to interpret agent outputs correctly.
Communication is critical. Share clear messaging that explains why the agent is being introduced, what success looks like, and how feedback will be used. Use town halls, demo sessions, and hands-on workshops to build trust and momentum. Capture user feedback systematically and incorporate it into the product backlog so users see their input reflected in subsequent releases. For a support team, this might mean showing how the agent reduces routine work so they can focus on complex customer issues.
Consider incentives for adoption that align with organizational goals. Incorporate agent usage and outcomes into performance review discussions where appropriate. Monitor adoption metrics such as active users, frequency of use, and task completion rates. Use these metrics as leading indicators for long-term value and adjust the rollout approach to address adoption barriers as they arise. If adoption is slow, dig into why - is the agent not trustworthy yet, is training insufficient, or is the workflow poorly designed?
Scaling Beyond 90 Days: Building a Sustainable Platform
After a successful 90-day rollout, plan how to scale the agent platform responsibly. Reuse the components that worked well such as connectors, governance templates, and observability pipelines. Build a catalog of approved agent blueprints that streamline future deployments. Create a central platform team that provides core services and enables decentralization of use case development by business units.
Govern the platform with a lightweight operating model that balances central standards and local flexibility. Define clear onboarding paths for new teams, provide templates and training, and enforce baseline policy checks automatically. Establish a quarterly review where platform performance, security posture, and compliance status are evaluated. Use this cadence to prioritize platform improvements and to retire outdated components.
Invest in developer experience. Better tooling reduces build time and improves consistency. Provide SDKs, deployment templates, and observability libraries that make it easy to stand up new agents following your deployment plan. Over time, a well-governed and user-friendly platform reduces marginal cost and increases the speed at which new value can be realized. Your second agent deployment should take 30 days, not 90.
Common Pitfalls and How to Avoid Them
Many organizations stumble when scaling agentic AI. Common pitfalls include unclear success criteria, over-engineering early prototypes, neglecting governance, and failing to plan for operational support. This deployment plan addresses these pitfalls directly through time-boxed validation, minimum viable agent designs, upfront guardrails, and operational runbooks.
Avoid feature bloat in the pilot stage by focusing on the smallest change that can produce measurable impact. Resist building broad autonomy before you have strong monitoring and human oversight. Ensure that stakeholders understand trade-offs and are prepared to accept incremental progress rather than expecting perfect solutions at launch. Lastly, plan for change in team structure and processes as the agent moves to production so that long-term support is sustainable. If your pilot was run by a small task force, who owns the agent in production?
Sample 90-Day Roadmap Template
Below is a condensed sample roadmap that follows the deployment plan structure. Use it as a starting point and adapt milestones to your organizational context and chosen use case.
Days 1 to 7: Stakeholder alignment, use case selection, success metrics definition, governance framework review.
Days 8 to 14: Sandbox provisioning, data access approvals, initial connectors, baseline testing setup.
Days 15 to 30: Prototype build, controlled testing with early users, pilot evaluation and go - no-go decision.
Days 31 to 45: Expand user set, improve data pipelines, enhance telemetry and logging, performance tuning.
Days 46 to 60: Harden governance and access controls, automate policy checks, finalize runbooks and escalation procedures.
Days 61 to 75: Performance validation, comprehensive integration testing, load testing, production readiness review.
Days 76 to 90: Production migration, stakeholder reporting and ROI analysis, scale planning and next use case roadmap.
Practical Tools and Templates for Your Deployment Kit
To operationalize your deployment plan, include templates that make execution repeatable. Suggested items are a project charter template, risk assessment checklist, data access request form, model performance dashboard template, runbook template, and a governance approval checklist. These artifacts streamline coordination and ensure the right questions are asked at each stage.
Also include sample queries and scripts for generating telemetry, a list of recommended metrics, and a decision rubric for human-in-the-loop interventions. Provide training materials that can be localized to different teams. Packaging these materials as part of your Rapid Deployment Kit reduces ramp-up time for subsequent pilots and helps maintain consistency across deployments. For example, a template for defining agent success criteria prevents teams from setting vague goals like "improve efficiency" and instead forces specificity like "reduce manual ticket categorization time by 40%."
Getting Started: Your Next Steps
Moving from experimentation to impact requires a packaged, time-boxed approach that balances speed and safety. The Rapid Deployment Kit outlined in this article is an actionable blueprint designed to reduce time to value while limiting operational and compliance risk. By structuring work into 30, 60, and 90-day sprints, you can validate assumptions quickly, harden systems incrementally, and scale with confidence when outcomes meet defined success criteria.
Start by identifying your highest-impact, lowest-complexity use case. This might be support ticket triage, lead qualification, knowledge retrieval, or workflow routing - choose something that directly improves a bottleneck in your operations. Assemble a small team of stakeholders, engineers, and the users who will interact with the agent. Define success metrics that matter to your business - time saved, error reduction, throughput, or customer satisfaction. Then commit to 30 days of focused work to prove the concept.
The discipline matters. Clear roles, a prioritized backlog, and a focus on measurable outcomes are the levers that convert pilots into production-scale deployments. Investments in modular architecture, telemetry, and developer experience pay dividends by lowering the marginal cost of future use cases. Equally important is the human element. Training, communication, and ongoing support ensure that users understand the agent as a collaborator rather than a black box. That mindset shift accelerates adoption and improves the quality of feedback that fuels subsequent iterations.
Governance is not a one-time checklist. Integrate it into your CI/CD pipelines and decisioning flows. Automate policy checks where possible and maintain a regular cadence for audits and risk reviews. This approach ensures that agents remain aligned with your organizational objectives and legal obligations as they evolve.
Finally, scale requires reusability. Capture what worked and create a catalog of blueprints, connectors, and monitoring patterns. Use your Rapid Deployment Kit to onboard new business units rapidly and apply lessons learned to accelerate future projects. With a disciplined deployment plan, you can reduce time to value, lower risk, and unlock sustainable operational improvements that compound over time.
If you are a founder or operations leader preparing to deploy agents at speed, start with a clear, time-boxed pilot that maps directly to business outcomes. Use the 30, 60, 90-day framework to manage expectations, prove value, and build the platform capabilities needed for scale. That approach transforms agentic AI from a strategic ambition into a pragmatic engine of sustained operational improvement.
Conclusion
The path from pilot to production is neither instantaneous nor risk-free, but it is navigable with the right framework. The 30–60–90 day Rapid Deployment Kit gives you a structured, repeatable methodology to move agentic AI from concept to operational impact without sacrificing safety, compliance, or team alignment. By anchoring each phase to measurable outcomes and building incrementally on validated assumptions, you compress the timeline to value while maintaining the rigor that production systems demand.
The organizations that will lead in agentic AI are not those that deploy the fastest - they are those that deploy sustainably. That means choosing the right first use case, investing in telemetry and governance from day one, and building a culture where humans and agents collaborate effectively. It means treating your pilot as a learning engine, not a one-off experiment. And it means recognizing that the real competitive advantage lies not in a single agent, but in your ability to rapidly iterate, learn, and scale across your entire operation.
Your 90-day blueprint is now in hand. The next step is commitment. Assemble your team, define your success metrics, and lock in your first use case. Execute with discipline, measure relentlessly, and be prepared to iterate. The organizations that move from pilot to production in 90 days - and continue scaling beyond - will establish a durable advantage in an era when operational agility is a core competitive asset.
The time to begin is now.
Next step
Book the Opportunity Sprint


