A.I. PRIME - Article
Troubleshooting Multi-Step Agent Workflows: Common Failure Modes and Proven Fixes
Troubleshoot agent workflow failures with proven diagnostics and fixes for context loss, tool errors, and race conditions.
Multi-step agent workflows are critical for modern operations teams, yet they fail regularly in production. Context loss, tool errors, race conditions, and permission failures can cascade into multi-hour outages that disrupt your entire operation. This troubleshooting guide provides a practical diagnostic framework and actionable mitigation recipes for the most common failure modes you'll encounter. You'll learn how to recognize patterns, apply rapid fixes that stabilize your agents, and implement durable architectural changes that prevent recurrence. Whether you're managing a Q3 surge or scaling your automation infrastructure, this guide equips your ops team with the patterns, checklists, and playbooks needed to restore throughput while maintaining safety and traceability.
Why Agent Workflow Failures Matter Now
Agent-driven systems coordinate multiple components, maintain evolving context across steps, and call external tools. When any part of that chain fails, the workflow can degrade silently or stop entirely. The operational cost is visible in delayed deliveries, reduced trust, and increased manual intervention. Early identification of failure patterns reduces mean time to recovery and prevents small issues from becoming major incidents. Learn more in our post on Troubleshooting Guide: Common Failure Modes in Multi-Step Agent Workflows and Fixes.
Agent workflow failures typically stem from three broad systemic causes. First, context loss where state does not persist or is misrouted between steps. Second, external tool errors where connectors or APIs return unexpected responses or degrade. Third, concurrency problems such as race conditions where timing differences produce inconsistent outcomes. Each cause has multiple manifestations and requires both tactical fixes and strategic changes to design and monitoring.
Understanding these root causes helps teams separate transient incidents from architectural flaws. A single stubborn error can be mitigated with a circuit breaker or retry policy. An underlying pattern of context loss suggests a need for redesign in how state is passed and validated. Investing time up front to classify failure modes reduces firefighting time later and keeps the pipeline stable during periods of high load.
High-Level Diagnostic Flowchart for Rapid Triage
Before applying any fix, establish a rapid diagnostic flow. This sequence helps you identify the dominant failure mode in under 15 minutes. Follow the steps in order to reduce wasted effort and apply the least invasive remedy first. Learn more in our post on Self-Healing Workflows Troubleshooting: Diagnose and Fix Common Failure Modes.
Confirm symptom and scope. Determine which workflows, users, and tools are affected. Is the failure isolated or system-wide?
Collect recent logs and traces. Gather the last successful run versus the failing run to compare differences. Note timestamps, context sizes, and API error codes.
Check for context divergence. Inspect state objects passed between steps and look for truncation, serialization errors, or mismatches in schema.
Examine external tool responses. Identify non-2xx responses, latency spikes, and quota errors from third-party calls.
Evaluate concurrency and timing. Determine whether steps are racing for shared resources or whether external events arrive out of expected order.
Apply a scoped mitigation. Use guarded retries, short-circuit fallbacks, or temporary configuration toggles to stabilize the environment.
Verify and escalate. Once stabilized, perform a controlled test to validate the fix, then plan a durable solution and update runbooks.
Following this flow reduces unnecessary countermeasures. For example, restarting an agent without checking an upstream API quota may only mask the real problem. The diagnostic flow prioritizes reproducible evidence and aims for the smallest change that brings the system back to a safe state.
Core Failure Modes, Detection Signals, and Immediate Fixes
This section breaks down specific failure modes with practical detection signals and immediate mitigation steps. Each failure mode also includes suggestions for durable remediation. The immediate fixes are designed to be safe for production environments and reversible. Learn more in our post on How to Automate Multi-Step Workflows with Agentic AI: A Practical 7-Phase Guide.
Context Loss and State Corruption
Symptoms: Inconsistent outputs, missing data in later steps, sudden drops in successful completions after a schema change. Context loss is one of the most common sources of agent workflow failures because multi-step workflows rely on accurate handoffs.
Detection signals: Compare the state object captured at the end of step N with the object consumed by step N+1. Look for missing fields, null values, unexpected data types, or size limits being reached. Check logs for serialization or deserialization errors and for base64 or JSON parse exceptions. Monitor for schema validation failures if you use strict contracts between steps.
Immediate fixes:
Introduce validation gates at handoffs. Implement a lightweight schema check that rejects malformed context with a clear error message instead of allowing downstream failures.
Enable conservative fallbacks. If a field is missing, have the downstream step use a default or requery the authoritative data store instead of failing quietly.
Temporarily pin schemas. Revert recent schema or serialization changes until you can deploy a gradual migration that supports both formats.
Durable remediation:
Adopt explicit versioned context objects. Include a context version number and migration paths when you change the shape of carried state.
Use transactional state stores where possible. Persist handoff checkpoints in a durable datastore so you can replay or repair context.
Automate contract tests. Run continuous integration checks that validate end-to-end handoffs under realistic loads to catch regressions early.
Tool Integration Errors and Flaky APIs
Symptoms: Intermittent failures at external calls, spikes in error codes, timeouts, or silent no-ops where tools return success but produce no side effects. These failures are especially frequent when downstream tools are rate-limited or undergo partial outages.
Detection signals: Monitor and alert on error rates, latency percentiles, and specific HTTP or RPC status codes. Correlate tool errors with deployment events and traffic surges. If a tool supports webhook or event streams, check for backlog growth or repeated retries.
Immediate fixes:
Apply exponential backoff with jitter. For transient errors, enable structured retries that reduce pressure on the tool and avoid synchronized retry storms.
Switch to a read-only or degraded mode. If the external tool provides limited functionality, route workflows to safe read-only paths to preserve data integrity.
Implement time-bounded fallbacks. Set conservative timeouts and, when appropriate, hand off to a human review queue to avoid losing work.
Durable remediation:
Build resilient connectors. Wrap third-party calls with adapters that translate status codes, implement retries, and provide standardized observability signals.
Implement circuit breakers. Temporarily stop calling a degraded tool and surface a clear failure message to downstream consumers while a retry policy resets.
Maintain capacity and quota dashboards. Track usage against quotas and notify teams before thresholds are exceeded, preventing sudden failures during peak periods.
Race Conditions and Timing Issues
Symptoms: Non-deterministic failures that occur only under certain load patterns. Steps observed to behave differently when executed concurrently, leading to duplicate side effects, lost updates, or deadlocks.
Detection signals: Identify patterns in logs where two or more agents touch the same resource near-simultaneously. Look for optimistic locking failures, duplicate transaction IDs, or inconsistent reads in a short window. Reproduce high-concurrency scenarios in a staging environment to confirm.
Immediate fixes:
Serialize critical sections. For shared resources, introduce short-lived locks or leader election to ensure only one agent performs a sensitive operation at a time.
Use idempotent operations. Design tool calls to be safe when repeated, returning the same result or a benign error if the side effect has already occurred.
Queue conflicting tasks. When possible, funnel operations through a controlled queue that preserves ordering and reduces simultaneous access.
Durable remediation:
Adopt optimistic concurrency controls. Use versioned writes and compare-and-swap semantics to detect and resolve conflicts explicitly.
Implement event sourcing patterns. Capture intent as immutable events and build up state deterministically, avoiding the ambiguity of concurrent direct writes.
Design for eventual consistency. Where strong consistency is not required, communicate expected convergence windows to consumers and build reconciler processes.
Authentication, Authorization, and Permission Failures
Symptoms: Sudden 401, 403, or permission-denied errors for agents that previously had access. These may follow credential rotation, role changes, or a change in token scopes.
Detection signals: Cross-reference the timestamp of the first failure against credential rotation events. Monitor token expiry times, refresh failures, and role binding changes. Audit logs for denied access attempts and service account changes.
Immediate fixes:
Roll back recent permission changes. If a permission modification is the cause, revert to the prior state while you investigate the scope of the update.
Rotate and reissue credentials correctly. Ensure refresh tokens are functional and that the agent obtains new credentials before expiry.
Provide a maintenance mode. Redirect affected workflows to a degraded path that does not require the missing permission, with manual oversight.
Durable remediation:
Automate credential health checks. Periodically validate the agent credentials and refresh behavior in non-production windows.
Use least privilege with service account boundaries. Limit blast radius by dividing roles across agents and services.
Document role changes and require approval. Treat permission changes as change-controlled events with rollback plans.
Observability and Monitoring Recipes to Detect Failures Earlier
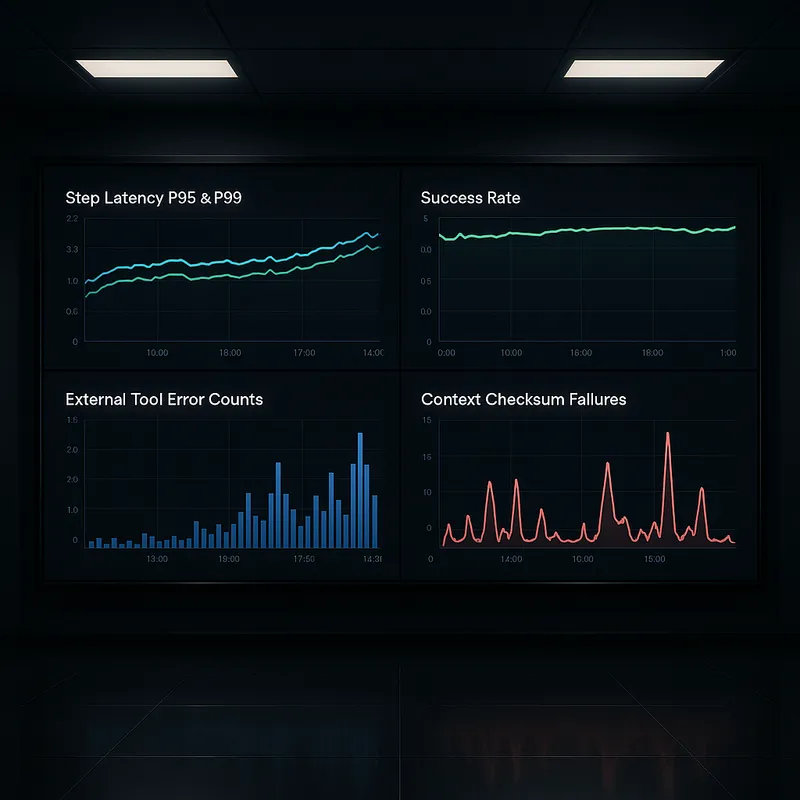
Effective observability is essential to prevent agent workflow failures from escalating. This section lays out concrete metrics, logs, and traces to instrument, plus alerts that teams should configure to detect anomalies early.
Key signals to instrument:
End-to-end success rate. Track percentage of workflows that complete without manual intervention.
Step-level latency. Measure p50, p95, and p99 durations for each step to detect growing tail latency.
Context integrity checks. Emit a lightweight hash of context payloads at handoffs to track unexpected divergence across runs.
External tool metrics. Record response codes, latency, and retries for each external integration separately.
Concurrency conflict rates. Count optimistic lock failures, duplicate ID detections, and queue reorders.
Alerting guidelines:
Alert on step-level error rate increases. Use a relative threshold to avoid noise from routine variability.
Use anomaly detection for latency spikes. Alert on sustained degradation in p95 or p99 rather than single brief spikes.
Notify on context checksum mismatches. A sudden increase in failed handoffs is a strong early warning of context-related agent workflow failures.
Tracing and logs:
Propagate a single correlation ID across steps. This makes it much easier to aggregate logs and traces for a single workflow instance.
Log inputs and outputs at each step with an opt-in policy. Avoid logging sensitive details but include enough metadata to reproduce state shapes.
Keep short-lived debug traces. For incidents, enable richer tracing for affected workflows to collect deeper insight without creating permanent noise.
By aligning alerts with how failures actually impact users, teams can reduce alert fatigue while focusing on the signals that matter for stability. Correlating telemetry across systems makes the diagnostic flow in earlier sections faster and more reliable.
Playbook Recipes: Step-by-Step Mitigations for On-Call Teams
When an incident is declared, teams need concise playbook steps they can follow under pressure. The following recipes are short, prioritized runbooks tailored to specific failure classes that commonly lead to agent workflow failures.
Playbook: Transient External Tool Degradation
Confirm tool status via its status endpoint and internal dashboards. If the tool is degraded, set incident priority based on business impact.
Apply circuit breaker: route new requests to a safe fallback or return a clear degraded status to callers. Do not retry aggressively.
Enable read-only or cached responses for non-critical reads. Serve best-effort data to maintain user experience.
Send a paged alert to the tool owners and your SREs with relevant logs and request IDs. Track the mitigation until the external service recovers.
Post-incident: analyze retry patterns and adjust backoff and timeouts. Consider adding secondary providers or cached alternatives.
Playbook: Repeated Context Loss Across Handoffs
Gather last N successful and N failed workflow traces for comparison. Look for differences in context version fields or serialization timestamps.
Pin the system to a stable schema via configuration. Reject non-conforming messages at the handoff gate while you debug.
Run a manual repair script to reconstruct context for failed instances where business continuity requires it.
Roll out a staged migration with backward compatibility and feature flags for new schema consumers.
Post-incident: add automated contract tests and a context checksum monitor.
Playbook: Intermittent Race Condition Causing Duplicate Side Effects
Identify the conflicting resource and throttle new requests to reduce pressure. This prevents further duplicates.
Enable idempotency keys at the API layer and deduplicate recent side effects where safe.
Introduce a short-term leader election that serializes access to the critical resource.
Deploy a reconciler job that compares the desired state to actual state and removes or consolidates duplicates safely.
Post-incident: apply optimistic locking or persistent queues for critical operations.
Scaling, Load Testing, and Preventing Regressions
Many agent workflow failures only appear under scale. Capacity planning and load testing should mimic real-world concurrency and error conditions. The practices below help teams surface fragile assumptions before they reach production.
Load testing recommendations:
Run stress tests that ramp the number of concurrent workflows while varying external tool latencies to replicate slow dependencies.
Include chaos scenarios. Inject brief API errors, increased latency, and token revocation events to validate resilience.
Simulate state drift and schema changes. Verify that the workflow handles mixed versions gracefully.
Regression prevention:
Make every behavioral change behind a feature flag. Release toggles let you roll forward or back safely when new agent workflow failures are detected.
Integrate synthetic canaries that run representative workflows every minute. These act as early detectors of subtle regressions impacting core flows.
Maintain runbooks with clear ownership. Ensure the on-call person knows which mitigations are safe and which require approvals.
Metrics to evaluate after load tests include per-step p99 latency, context corruption rate, retry volume, and change in external tool error patterns. Use these to validate that infrastructure scaling and retries behave as expected rather than amplifying failure modes.
Runbook Items for Durable Fixes and Governance
After stabilizing a failure, teams should prioritize durable fixes. This prevents recurrence and reduces firefighting load during peak periods. The list below provides a governance-oriented checklist that helps teams move from quick mitigation to permanent resolution.
Root cause analysis within 72 hours. Collect triage notes, reproduce the bug if possible, and document the chain of events that led to the failure.
Define a remediation owner and timeline. Assign a single owner to track the fix through implementation, testing, and rollout.
Plan a controlled rollout. Use feature flags or phased deployment to minimize blast radius and to validate the fix under production conditions.
Update monitoring and alerts. Add specific alerts that would have detected the incident earlier and tune thresholds to reduce false positives.
Schedule a postmortem blameless review. Share findings, lessons learned, and the updated runbook entry with affected teams.
Improve test coverage. Add contract tests, integration tests, and chaos tests to cover the scenario.
Good governance converts firefighting into learning. By capturing the incident lifecycle and tracking improvements, teams make agent workflow failures less likely and less painful.
Hands-On Checklist: Immediate Actions for an On-Call Engineer
Use this checklist as a pocket guide during an incident. The steps are intentionally concise so they are easy to follow under pressure.
Identify scope: which workflows, users, and integrations are impacted.
Collect correlation IDs and recent traces for one failing instance and one working instance.
Check external tool health and quotas.
Inspect context at the most recent handoff and the input for the subsequent step.
Apply the least risky mitigation: schema pin, circuit breaker, temporary leader election, or idempotency enforcement.
Confirm stabilization and run a controlled test through the full workflow.
Open a root cause ticket and assign ownership for durable fixes.
Following these steps reduces the cognitive load on responders and increases the chance of restoring service quickly while preserving data integrity and traceability.

Best Practices to Reduce the Frequency of Agent Workflow Failures
Prevention matters. Practical design and operational practices reduce the number and impact of agent workflow failures. The items below represent prioritized investments that deliver a high return in stability.
Contract-first design. Treat the shape of context passed between steps as a first-class contract and version it explicitly.
Idempotency by default. Design operations so repeated execution is safe and will not produce harmful side effects.
Centralized observability. Correlation IDs, consistent logging formats, and aggregated dashboards make triage faster.
Feature flags for behavior changes. Short-lived toggles enable safe rollouts and quick rollback during incidents.
Scheduled chaos engineering. Regularly inject faults into non-critical paths to harden systems and reveal weak assumptions.
Comprehensive runbooks. Keep actionable, concise playbooks close to the alert and test them in game days.
Combining these practices with a culture that values post-incident learning ensures that agent workflow failures become rarer over time and that teams are well-prepared when incidents occur.
Conclusion
Agent workflow failures are an operational reality for systems that coordinate stateful, multi-step processes across internal and external services. The patterns described in this guide help teams triage and remediate the most frequent causes: context loss, tool errors, and race conditions. Rapid diagnosis begins with clear evidence collection: capture logs and traces, compare successful and failed runs, and correlate failures with changes in schema, permissions, and external tool health. The diagnostic flow and playbooks help responders apply the least invasive fix that stabilizes production while retaining the ability to perform root cause analysis afterward.
Immediate mitigation techniques include schema pinning, conservative fallbacks, exponential backoff with jitter, circuit breakers, and idempotency enforcement. These provide a safety net that preserves data integrity and reduces the risk of cascading errors. Equally important is the investment in observability. Instrument end-to-end success rates, step-level latency, context integrity checks, and external tool metrics. Propagate a correlation ID across every step and ensure logs capture inputs and outputs at key handoffs. This telemetry not only speeds recovery during incidents but also informs capacity planning, load testing, and regression prevention strategies.
Longer-term remediation transitions temporary mitigations into permanent fixes. Versioned context objects, resilient connectors, optimistic concurrency, and controlled queues address root causes rather than symptoms. Introduce contract testing and synthetic canaries to catch regressions before they reach production. Maintain a clear incident governance workflow: assign remediation owners, schedule blameless postmortems, and update runbooks with the lessons learned. Adopting these practices reduces the frequency of agent workflow failures and shortens mean time to recovery when problems occur.
Operational readiness also requires rehearsal. Runbooks only help if they are practiced. Schedule regular drills and chaos exercises that replicate the most likely failure modes, and review the outcomes with stakeholders. This ensures that teams can stabilize agents quickly during peak periods and beyond. When you combine preventive architecture, real-time observability, and practiced incident response, the organization gains predictable reliability. That stability improves customer trust, reduces manual toil, and frees teams to focus on feature work rather than firefighting recurring agent workflow failures.
Next step
Book the Opportunity Sprint


